

























Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania
Bazy danych nie mogły by funkcjonować gdyby nie indeksy. Można powiedzieć że nawet najbardziej sprytna metoda dostępu do jakichkolwiek danych bez jakiejś formy indeksowania nie była by wydajna
Wystarczy pomyśleć ile czasu zajęło by odnalezienie Pani Marii Kowalskiej z domu Pietraszak urodzonej w Nowej Roli w 1982 roku a obecnie zamieszkałej w Wrocławiu. Algorytm bez indeksu zakłada że będziemy odwiedzać każdy Wrocławski dom i każde mieszkanie po kolei i pytać czy nie mieszka tu taka pani. W końcu znajdziemy, ale … nie zbyt szybko. Z pomocą przychodzi tu nam indeks, indeks stanowi mały i uporządkowany wg jakiś kryteriów spis w którym szybko znajdziemy daną osobę (np. alfabetycznie po nazwiskach i imionach) a następnie spis ten zawiera jakieś bezpośrednie wskazanie które pozwoli dotrzeć szybko do danej osoby w tym przypadku pod jej adres.
W bazach danych jest podobnie. Mamy np. spis wszystkich zamówień firmy, po jakimś czasie są ich miliony i zajmują gigabajty przestrzeni na dysku, jak zatem odnaleźć jedno konkretne zamówienie znając jego numer. Bardzo prosto. Tworzymy indeks z numerów zamówień, aktualizujemy go za każdym razem jak dodajemy lub usuwamy zamówienie, tak aby jego zawartość zbyła zgodna z zawartością tabeli zamówień. Jak potrzebujemy znaleźć zamówienie, wczytujemy indeks (jest zdecydowanie mniejszy od tabeli z danymi), szukamy w nim gałęzi o odpowiednim numerze (idzie to szybko bo indeks jest uporządkowany) i już mamy namiary na konkretne miejsce w tabeli gdzie znajduje się nasze zamówienie. W bazie Postgres wygląda to tak:
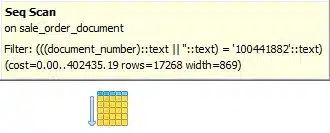
zapytanie realizowane bez użycia indeksów, (chodzimy po domach i pytamy), ma koszt ok 400tyś, natomiast:
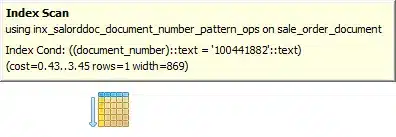
zapytanie z użyciem indeksów ma koszt ponad 100 000 razy mniejszy!!!
Czy zatem w tym przesłodkim sielankowym obrazie coś może pójść nie tak? Niestety może. W naprawdę dużych środowiskach kiedy danych jest naprawdę dużo, indeksy stają się … naprawdę duże. Trudno mówić wtedy z taką łatwością „wczytam sobie indeks” bo może się okazać że indeks pomimo że wielokrotnie mniejszy od danych, to i tak jest już za duży. Co wtedy? Rozwiązań jest wiele, można np. dzielić duże tabele na wiele mniejszych tabel (partycjonowanie), albo okresowo czyścić operacyjną bazę danych z danych archiwalnych i przenosić je do hurtowni danych. Wszystko to wymaga dosyć zaawansowanych działań. Jest jednak jedno ciekawe rozwiązanie dostępne w bazie Postgres od wersji 9.5 które w dosyć prosty sposób może uratować sytuację i to bez wielkiego wysiłku.
Domyślnie w bazie Postgres tworzone są indeksy typu BTREE, w skrócie oznacza to że indeks taki pozwala na mikro-sekundowe czasy wyszukiwania, w naszym przykładzie jest to np. 120µs na wyszukanie zamówienia, kosztem tego rozmiar takiego indeksu jest duży i wynosi np. 120 MB przy rozmiarze tabeli 3,2 GB. Indeksu tego typu są doskonałe do operowania na aktualnych, operacyjnych danych, gdzie tak dobre czasy są nam potrzebne. Zaznaczmy że dostęp do starszych zamówień (z punktu widzenia użytkownika zamówień archiwalnych), mógłby się odbywać w czasie dłuższym.
W Postgres od wersji 9.5 wprowadzono nowy rodzaj indeksów, indeksy BRIN. Indeks ten:
- jest przeznaczony do indeksowania dużych tabel,
- najlepiej sprawdza się dla kolumn których wartości zmieniają się w czasie w sposób konsekwentnie malejący lub rosnący,
- daje dłuższe ale jednak dalej krótkie czasy wyszukiwania, w naszym przykładzie jest to np. 29ms,
- przy rozmiarze indeksu ok 10 000 razy mniejszym niż index BTREE, np. 16 kB,
- aktualizacji indeksu BRIN podczas zmiany zawartości tabeli jest wielokrotnie szybsza niż aktualizacja indeksu BTREE.
Koncepcja jest taka: zakładamy dwa indeksy, index BRIN na całą zawartość tabeli zamówień:
CREATE INDEX inx_salorddoc_document_number_b ON sale_order_document
USING BRIN (document_number);
oraz index BTREE na dokumenty z ostatnich 12 miesięcy:
CREATE INDEX inx_salorddoc_document_number_a ON sale_order_document
USING BTREE (document_number)
WHERE document_date > '2016-02-01′
z założeniem że drugi index będziemy przebudowywać raz na miesiąc podając mu nowy zakres daty dokumentów.
W efekcie otrzymujemy:
- bardzo szybkie czasy wyszukiwania dokumentów w aktualnym okresie
- całkiem niezłe czasy wyszukiwania dokumentów archiwalnych
- mały i prawie stały rozmiar indeksów (index BRIN jest mały a indeks BTREE jest zawsze tylko za 12 miesięcy)
- i to wszystko nieznacznym kosztem
Podsumowując powiem tylko, że to nie wszystkie zastosowania indeksów BRIN i że po raz kolejny jestem pod dużym wrażeniem pracy deweloperów Postgresa.
