
























Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania
Jednym z aspektów wysokiej wydajności systemów jest ich zdolność do skalowania się poprzez wydajną obsługę operacji równoległych. Z różnych powodów systemy nie skalują się w nieskończoność liniowo, często jest jeszcze gorzej, skalują się do pewnego momentu i dalej koniec, stop! Pytanie, dlaczego tak się dzieje? Pomijając oczywiste błędy algorytmów, a skupiając się wyłącznie na problemach tkwiących architekturze, chciałbym poruszyć temat jednego z największych wrogów skalowalności mianowicie dostępu do zasobów współdzielonych. Od razu zaznaczam, że nie zajmę się wyłącznie opisaniem problemu, ale postaram się zaprezentować przynajmniej jedno skuteczne rozwiązanie, więc jest całkiem możliwe, że warto doczytać do końca :).
Zasób współdzielony jest to element systemu informatycznego o dostęp do którego, może rywalizować wiele żądań, a dostęp ten nie może odbywać się równolegle. Z samej natury rzeczy zakładając, że każde żądanie potrzebuje posiadać taki dostęp przez niezerowy czas i w tym czasie inne żądania muszą czekać, otrzymujemy „wąskie gardło” w skalowalności.
Przykładem takiego zasobu może być wiersz w bazie danych zawierający pewne informacje, które muszą być aktualizowane „online”, jak wiadomo aktualizacja wiersza w jednej transakcji, (przy zwyczajowych poziomach separacji transakcji) blokuje jego aktualizację przez inne równoległe transakcje, co w prosty sposób zmienia ten wiersz w potencjalne „wąskie gardło”. Oczywiście metody klasyczne polegające na dbaniu o jak najkrótsze transakcje, czy jak największej gradacji blokowanych zasobów są skuteczne, ale tylko w pewnym zakresie. Można matematycznie udowodnić, prostym wzorem, kiedy system na pewno przestanie się skalować, a czasy trwania operacji zaczną narastać. W prostym przykładzie, zakładając czas trwania od blokady wiersza do końca transakcji równy Tb, to do 1s/Tb transakcji na sekundę mamy pewne szanse na utrzymanie stałych czasów realizacji żądań, powyżej tej ilości czasy trwania żądań zaczną narastać, początkowo nieznacznie, dalej niestety coraz bardziej stromo. Sytuację obrazują poniższe schematy.
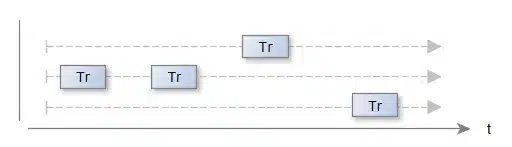
Na pierwszym schemacie widzimy trzy sesje, mówiąc inaczej trzech klientów, oraz ich żądania umieszczone w czasie i opisane czasem trwania Tr, na potrzeby przykładu pokazujemy tylko te czasy, które związane są z dostępem do zasobu współdzielonego, jak widać sytuacja jest optymistyczna, wszystkie żądania realizowane są w założonym czasie, żadne z nich nie zakłóca działania innych żądań, widać, że system tak skonstruowany i obciążony ma jeszcze wolną „moc”.
Drugi schemat:
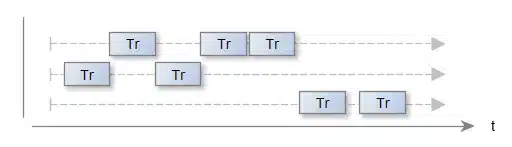
opisuje podobną sytuację, ale widzimy, że zasób współdzielony wykorzystywany jest maksymalnie, żądania ułożyły się tak szczęśliwie (rzadko tak bywa), że żadne z nich nie zakłóca działania innych żądań, nie mniej jednak brakuje tu już widocznego „zapasu”.
Na trzecim schemacie:
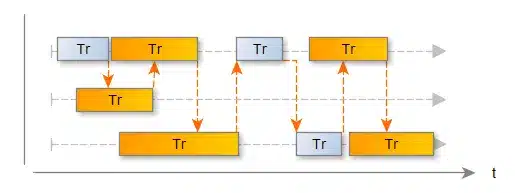
widzimy, że pomimo tej samej ilości żądań a w związku z ich jednoczesnym występowaniem niektóre żądania trwają znacznie dłużej. Pomarańczowa strzałka pokazuje miejsca przekazania dostępu do zasobu współdzielonego. Co warto zauważyć system cały czas charakteryzuje się maksymalną teoretyczną przepustowością 1s/Tb żądań na sekundę, jednak czasy trwania żądań są dłuższe i mogą przy rosnącej ich ilości, oraz rosnącej ilości klientów rosnąć o rzędy wielkości osiągając w najgorszym przypadku nawet 1s/Tb*Sc (gdzie Sc to liczba równoległych sesji).
Jak zatem skutecznie pozbyć się blokowania zasobów współdzielonych? Metod jest wiele. Przyglądnijmy się tym najpopularniejszym.
Pierwszą metodą, a raczej obejściem problemu jest powszechnie stosowana dbałość o skracanie czasu trwania transakcji, a dokładniej skrócenie czasu trwania od założenia blokady na wiersz (UPDATE, czy SELECT FOR UPDATE) do końca trwania transakcji (COMMIT), zgodnie ze wzorem 1s/Tb skracając ten czas 5 razy mamy 5 krotny wzrost przepustowości. Tego rodzaju rozwiązanie poprawia skalowalność, a dbałość o krótkie transakcje jest powszechną praktyką. Nie mniej jednak nie załatwia to sprawy, wyłącznie przesuwając granicę wystąpienia problemów.
Pierwsze prawidłowe i kompletne podejście do problemu wynika z prostej zasady, nie stosujmy tego, co nas ogranicza, więc skoro zasoby współdzielone ograniczają wydajność, unikajmy ich w naszych systemach. Spotkałem się z rozwiązaniem w „systemie” stworzonym w warunkach akademickich gdzie w sklepie internetowym widoczna była ilość zamówień i ich pozycji złożonych od początku otwarcia sklepu, wartości te miały pokazywać, że sklep jest wybierany przez bardzo wielu użytkowników, w związku z tym jest taki „super”. Nie dyskutuje z samym pomysłem, ale sposób realizacji polegał na tym, że dodanie pozycji zamówienia powodowało UPDATE jednego wiersza w tabeli SKLEP i poniesienie wartości w kolumnie ILPOZZAM o 1, analogicznie działo się przy dodawaniu samego zamówienia. System ten jak widać ma ograniczoną skalowalność „by design”, zakładając czas trwania dodania pozycji zamówienia równy 50ms, system taki maksymalnie przyjmie 20 pozycji na sekundę, a już przed osiągnięciem tego wyniku użytkownicy mogą odczuwać znaczne wydłużenia czasu trwania ich żądań. Jak to naprawić?
Jeżeli informacja o ilości zamówień nie musi być całkiem „online” można zrezygnować z ciągłego UPDATE, a okresowo pomocą Timer’a/Cron’a uruchamiać polecenie UPDATE powodujące jej uaktualnienie na podstawie danych z SELECT. W opisywanym przypadku taka informacja aktualizowana okresowo (np. co godzinę) jest więcej niż wystarczająca, likwiduje ona całkowicie zasób współdzielony z systemu, likwidując barierę skalowalności. Opisany tu schemat działania określamy jako OUA (One Update After) i jest to jedna ze skutecznych metod pozbywania się zasobów współdzielonych z systemów bazodanowych, jej wadą jest pewne opóźnienie w otrzymywaniu aktualnej informacji.
Drugą skuteczną metodą jest metoda CUTI (Convert Update To Insert), metoda ta polega na rezygnacji z poleceń UPDATE wykonywanych „online” jak w poprzedniej metodzie, ale z dodaniem poleceń INSERT, które pozwalają zachować dostęp do w pełni aktualnej informacji. Od razu może paść pytanie o koszty, skoro robimy dodatkowe INSERT to czy nie zwiększamy zużycia zasobów bazy danych? Nie dzieje się tak dlatego, że rezygnujemy z UPDATE, większość baz danych „wersjonuje” wiersze, co powoduje, że przy UPDATE i tak powstaje nowa wersja wiersza i koszt jest podobny jak przy INSERT. Rozważmy tabelę:
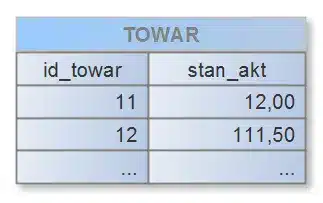
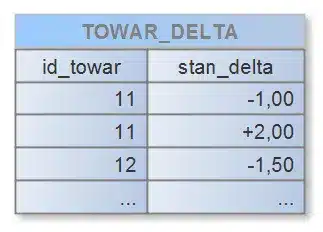
W systemie, który przy każdej transakcji przyjęcia lub wydania towaru aktualizowałby stan kolumny „stan_akt” poleceniem UPDATE, wiersze z tej tabeli stałyby się zasobami współdzielonymi, ograniczając skalowalność. Rozwiązaniem jest dodanie tabeli pomocniczej, widoku, oraz prostego skryptu uruchamianego okresowo. Zacznijmy od tabeli, do której zapisywać będziemy każde zdarzenie zmiany stanu towaru z pomocą INSERT:
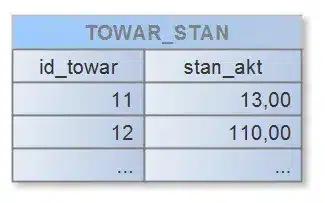
Oraz widoku, który będzie zawierał „online” informację o aktualnym stanie towaru:
W pseudo kodzie SQL definicja tego widoku mogłaby wyglądać tak:
CREATE VIEW towar_stan (id_towar, stan_akt) AS
SELECT
t.id_towar,
t.stan_akt + (SELECT sum(stan_delta) FROM towar_delta WHERE
id_towar = t.id_towar)
FROM towar t
Oczywiście mamy tu pewien koszt związany ze zwiększonym czasem odczytania stanów aktualnych rosnącym wraz ze wzrostem ilości wierszy w tabeli „towar_delta”. Jednak tu z pomocą przyjdzie nam skrypt uruchamiany okresowo w postaci:
SET transaction_isolation = repetable read;
BEGIN;
UPDATE towar_stan t
t.SET stan_akt = t.stan_akt +
(SELECT sum(stan_delta) FROM towar_delta WHERE
id_towar = t.id_towar)
WHERE
t.id_towar in
(SELECT DISTINCT id_towar FROM towar_delta);
DELETE FROM towar_delta;
COMMIT;
Skrypt wykonuje „czarną robotę” aktualizując stany oraz czyszcząc tabelę delt. Robi to rozsądnie, modyfikując stan tylko tych towarów, których nastąpiły zmiany stanu, oraz dbając o niezmienność informacji w bazie danych w trakcie swojego działania. W ten sposób skutecznie pozbywamy się zasobu współdzielonego, zachowując świeżość informacji przy niewielkim koszcie.
Na koniec bądźmy troszkę dociekliwi i poszukajmy odniesień tego rozwiązania do innych wzorców architektonicznych. Wprowadziliśmy zapis do tabeli a odczyt z widoku … czyli pewne rozdzielenie operacji zmiany danych i ich odczytu na jakby osobne stosy, a to między innymi postuluje architektura CQS (Command Query Separation) czy CQRS (Command Query Responsibility Segregation). Spojrzeliśmy także na zmianę stanu towaru jako na powstanie (INSERT) zdarzenia powstania różnicy, a nie samej zmiany (UPDATE) stanu, a to między innymi postuluje architektura ES (Event Sourcing). Czyż to nie jest naprawdę ciekawe?!
